

{kind=link}
Where the real pain lives
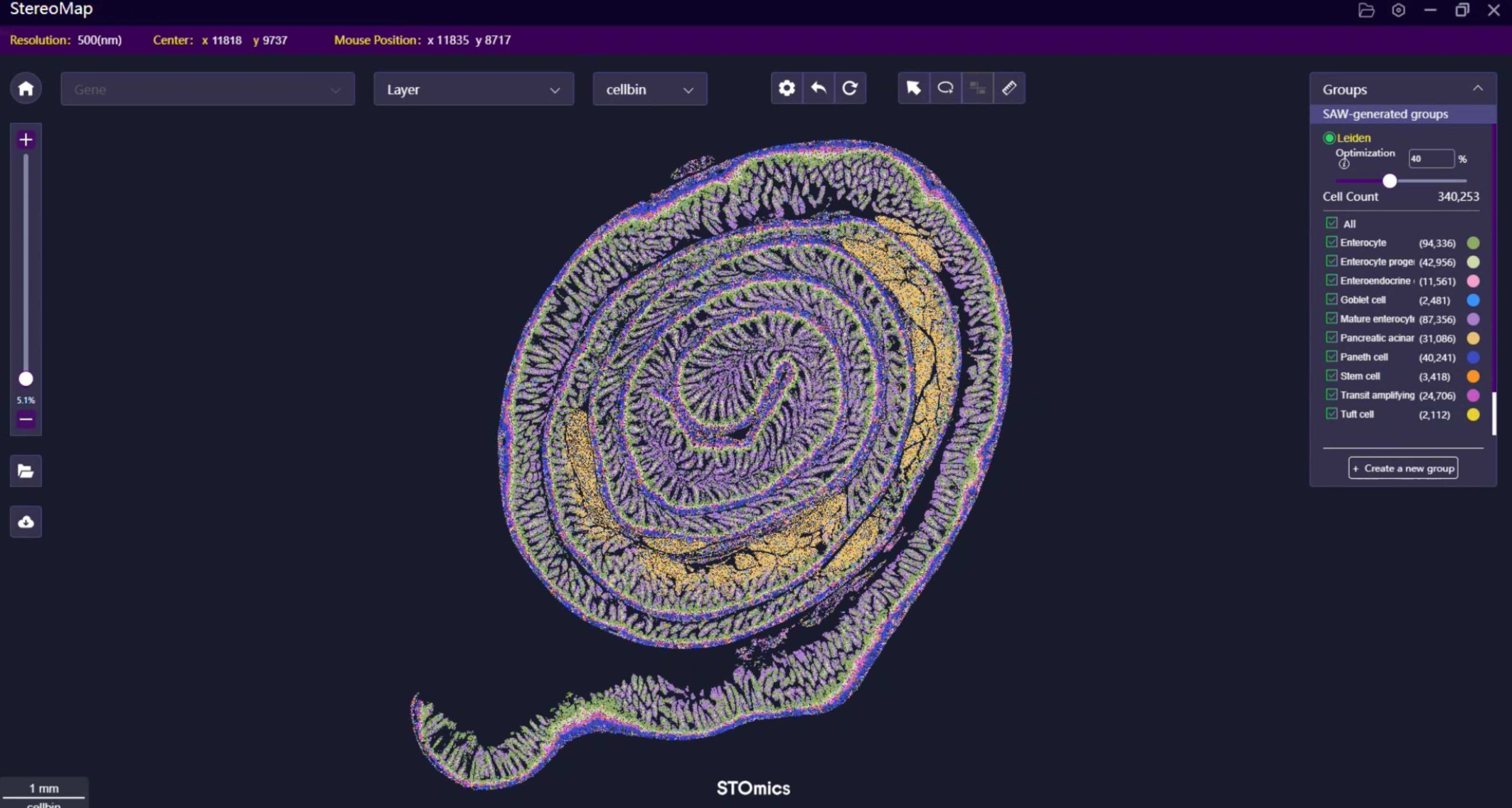
I was cutting sections at 7 AM in a small pathology suite in Boston when a rack of blocks told me everything I needed to know: stained slides looked fine, but the spatial maps were noisy and spotty. I began testing FFPE spatial transcriptomics that week, and I also evaluated the FFPE Transcriptomics Solution across workflows to see why our reads kept failing QC. During a tumor panel run (96 samples, June 2021) the RNA integrity numbers dropped and mapped reads fell by about 50% after our routine deparaffinization — what options actually fix that without burning time and money?
I say this from over 15 years moving things through labs and into production: formalin crosslinking and fragmented RNA are not new problems, but the hidden cost shows up in library prep yield and spatial resolution. I remember a pilot in March 2022 where switching microtome blade type and tweaking antigen retrieval cut our dropouts by nearly a third; that was a concrete, measurable win. The typical pitfalls I see are predictable — uneven sectioning, inconsistent barcoding, and suboptimal reverse transcription — yet teams still treat them as isolated quirks instead of systemic issues. For context, I ran a head-to-head with a Leica microtome and an alternate cryosection setup, and the difference was clear on mapped read percentages. No joke: small procedural changes translate to 10–40% differences in usable data (library prep and RNA integrity matter). (Hands-on detail: I logged samples, dates, and reagent lots for traceability.)
What’s Next?
Future-ready choices I watch — and three metrics to judge them
Now I shift forward. I compare platforms by three practical axes and I want you to use the same checklist: consistency, actionable resolution, and end-to-end throughput. Consistency means reproducible barcoding across runs so that spot-level counts don’t drift; actionable resolution is about whether spatial resolution and transcript capture let you resolve microenvironments (not just produce prettier maps); throughput covers actual samples per week after accounting for QC failures — because throughput drops are real cost. When evaluating new FFPE methods, I look for clear data on RNA integrity retention and percent mapped reads after library prep; those numbers predict whether a method will survive routine use. I’ve run comparative trials where one kit kept mapped reads above 65% while another slipped to 35% under identical input — that was in October 2022 at a mid-size clinical lab. I also care about hands-on time, vendor support (fast trouble-shoot), and whether protocols tolerate variable tissue thickness — tiny practical points that save days. Short sentence. Then a longer one to balance rhythm — I test implementation on at least 24 archived blocks before scaling.

To close with concrete evaluation metrics (use these): 1) percent mapped reads after library prep (target >60% for FFPE), 2) spatial resolution effective at the cell-cluster level (validated in published slides or in-house experiments), and 3) overall sample throughput accounting for re-runs (samples/week post-QC). These are simple, measurable, and they expose hidden costs fast. We choose tools by those outcomes, and I recommend running a small but strict pilot (24–96 blocks) before committing. I’ll keep iterating; you will too — and if you want a reference point, check solutions from stomics.